
Es gibt keinen Best-Case, wenn es um die technische Einstellung der Settings geht. Je nach thematischem Schwerpunkt, Größe der Internetpräsenz können verschiedene Strategien zur richtigen Handhabung von URLs (mit und ohne Parameter) zielführend sein. Wichtig ist allerdings, dass meine eine einheitliche Struktur verfolgt, um
- das Crawling Budget effizient zu managen und wichtige Seiten stärker crawlen zu lassen
- um Duplicate Content zu vermeiden und dadurch u.a. mögliche Rankingpotentiale nicht zu verschenken
- die Ladegeschwindigkeit durch effizientes Crawlen zu garantieren
- Fehler zu vermeiden, die zu Rankingverlusten und weniger Traffic führen
- Eine saubere Struktur zu haben, mit der der Linkjuice durch wichtige Seiten durchfließt
- Den Weg für effiziente Offpage Maßnahmen und Content Optimierungen zu ebnen
- Eine vertrauenswürdige Seite ohne Baustellen für Google zu hinterlassen
Für das richtige Handling mit Parametern wurden hier mehrere robots Settings in den Fokus geworfen. Darunter gehören
- Indexierungsstatus mit Index/noindex
- Linkjuice Beeinflussung durch follow/nofollow
- Die Nutzung des Canonical Tags zur Handhabung von Duplicate Content
- robots.txt Anpassungen zur Regulierung des Crawlings
- Die richtige Handhabung von hreflang Einstellungen
- Besonderheiten bei verschiedenen Status Codes, insbesondere Redirects
Dabei werden verschiedene Beispiele von verschiedenen Internetpräsenzen unterschiedliche Handhabungen aufgezeigt und die Vorteile und Nachteile dargestellt. Wenn du mehr zu diesem Thema erfahren willst, lass es mich gerne wissen. Gerne stehe ich dir als SEO-Berater zur Seite.
Table of Contents
Einstellung der Seiten mit Indexierungsstatus Index/Noindex in Verbindung mit Follow/Nofollow
Jeder SEO kennt diese Arten der Steuerung von Seiten zur Regelung der Indexierung sowie zur Steuerung des Linkflusses innerhalb der Seite. Zur Vereinfachung von Beispielen habe ich einige große Online Shops mal herangezogen, wo das schön gehandhabt wurde und wo gleichzeitig auch die unterschiedlichen strategischen Optionen sichtbar werden.
Mögliche Einstellungen sind je nach strategischer Ausrichtung und Gestaltung der Seite möglich:
Index/Follow
- Gilt einfach gesagt für alle Seiten, die man im Index sehen will und wo der Linkjuice reinfließt. Typischerweise sind alle relevanten Seiten, die strategisch von hoher Bedeutung sind.
- Paginierte Seiten mit News – Charakter bei Zeitungen und Magazine!
- Eher unüblich, aber durchaus denkbar: Aus strategischen könnte es durchaus interessant sein, parametrisierte URLs in den Index vereinzelt aufzunehmen
Index/nofollow
- Eigentlich sind interne Nofollow Links auf übergreifender Ebene unüblich. Aber bei bestimmten Seiten wie Advertorials wäre so eine Variante möglich. Empfehlenswert ist die Einstellung nicht.
Noindex/nofollow
- Bei Seiten, die man nicht im Index sehen will und an die auch keine Linkpower vererbt wird. Kann je nach Zielsetzung und Intention unterschiedlich sein.
- Typisch sind Seiten wie Impressum und Datenschutz, wenn Google den Links auch nicht folgen soll. Das ist von Fall zu Fall unterschiedlich.
Noindex/follow
- Tag-Seiten auf noindex/Follow stellen
- HTML Sitemap: hat im Index nichts zu suchen, aber die Links drauf sind von hoher Bedeutung
- Impressum, Datenschutz sollte noindex gestellt werden. Wenn wichtige Links drin enthalten sind, kann ruhig auf follow gesetzt werden.
- Verteilerseiten wie Glossare, wenn man sie nicht im Index will (ist jedem selbst überlassen)
- Nicht immer eindeutig: Für gewöhnlich sind URLs mit Filterparametern auf noindex, follow zu stellen. Es gibt allerdings auch andere Beispiele, wo es anders gehandhabt wird.
Kombination Indexierungsstatus mit Canonical Tag bei Parameterseiten
Der Canonical Tag wird bei Seiten mit doppeltem Inhalt eingesetzt und verweist auf das Original. Der Google Crawler kann somit zwischen Kopie und Original, der „kanonisierten“ Seite unterschieden. Der Canonical Tag sollte NUR bei Duplicate Content zum Einsatz kommen.
In der Regel wird der Canonical Tag im Header einer Seite eingesetzt:
<link rel=”canonical” href=”http://www.beispiel.de/original-url”/>
Eine schneller Quick Check ist mit Freeware Tools wie Open SEO Stats für Google Chrome möglich. Hier sind einige auserwählte Beispiele:
Noindex/follow + Canonical
Eigentlich in dieser Kombination von Google nicht empfehlenswert, aber trotzdem wird’s sehr häufig gehandhabt. Die Filterseite wird auf noindex gestellt, aber der Referrer geht auf die Ursprungsseite, damit diese in den Index gelangt.
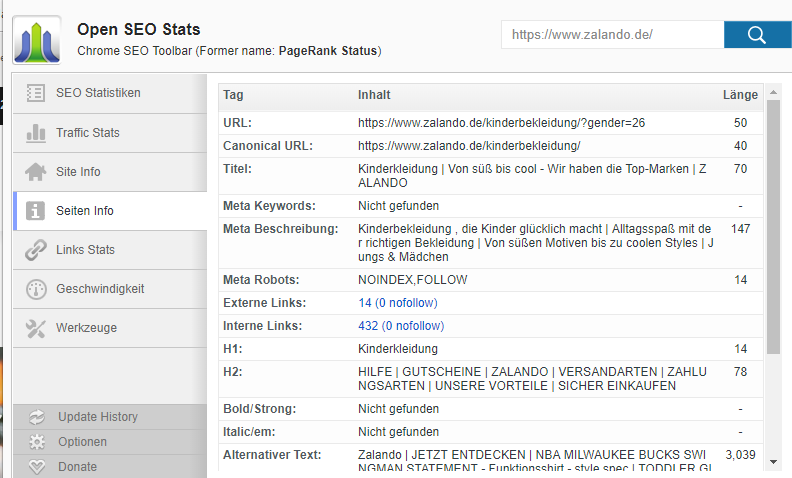
Folgende Optionen ergeben sich bei Seiten mit Filterparametern:
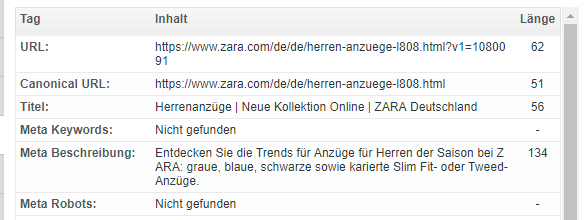
Index/Follow + Canonical Tag
- in Shops bei Produktseiten bei Neugenerierung von neuen Filter-URLs, da Duplicate Content durch verschiedene URL-Varianten erzeugt wird, z.B. durch Kanonisierung des Basisprodukts ohne Filter
Vorteil: klare eindeutig Zuordnung eines Produkts
Nachteil: Generierung einer Vielzahl von URLs mit zunehmender Belastung für das Crawl Budget
Beispiel: https://www.zara.com/de/de/herren-anzuege-l808.html?v1=1080091
mit Canonical Tag auf https://www.zara.com/de/de/herren-anzuege-l808.html
Einsatz der robots.txt bei Filterseiten
Hier ist die Wahrscheinlichkeit einer falschen Einstellung keine Seltenheit. Die Nutzung der robots.txt sollte im Vorfeld genau analysiert werden, um Fehler zu vermeiden. Die robots.txt ist eine Textdatei, mit der bestimmte Verzeichnisse, Dateien oder die ganze Domain vom Crawling abgehalten werden. In der Regel ist sie am Ende einer Domain mit www.domain.de/robots.txt abrufbar
- txt: hat Einfluss auf das Crawling, nicht auf die Indexierung
- Für Indexierung und Nichtindexierung sind die Meta-Tags verantwortlich
Wann macht eine robots.txt Sinn?
Der Ausschluss kann verschiedenste Gründe haben und jede Interpräsenz ist in ihrer
- Bei sehr großen Seiten, wo das Crawl-Budget regelrecht ausgelastet wird und andere robots-Einstellungen nicht effizient wirken, wäre zumindest der Einsatz der Crawlingsteuerung zu überlegen.
- Sie wird eingesetzt, um ganze Verzeichnisse auszuschließen. Hierbei ist zu beachten, dass Verzeichnisse am Ende zwingend mit einem „/“ ausgeschlossen werden. Sonst sperrt man bei /such statt seite.de/such/ auch www.seite.de/suchergebnisse/ oder www.suche.de/suchseiten/ aus.
- Nicht unüblich ist der Ausschluss von Suchergebnisseiten, vgl. z.B. https://www.monster.de/robots.txt
- Bei „Testverzeichnissen“, bei der bestimmte Seiteninhalte auf Nutzererfahrung getestet werden und für bezahlte Kampagnen wie Google Ads oder Facebook getestet werden.
Häufigste Fehler beim Einsatz der robots.txt
- txt wird fälschlicherweise als alternative Option für noindex genutzt. Wenn Seiten aus dem Index entfernt werden sollen, geht der erste Schritt zunächst über die Einstellung über noindex.
- Die Robots.txt sollte nicht in einer großen Menge aufgebläht werden. Die Gefahr vor Fehlern wächst mit zunehmender Anzahl der Einstellungen.
- Es kann durchaus sinnvoll sein, die Sitemap.xml in die robots.txt aufzunehmen. Dadurch wird dem Crawler klar aufgezeigt, welche URLs gecrawlt werden. Voraussetzung ist, dass die URLs in der Sitemap Statuscode 200 haben und einen Self-Canonical Tag aufweisen. Eine fehlerhafte Sitemap erhöht die Wahrscheinlich von Crawlingproblemen. Zudem sollte die Sitemap regelmäßig automatisiert geupdatet werden.
Einsatzbeispiele bei Filterseiten mit robots.txt
- https://www.zalando.de/robots.txt: die Seite schließt kundenspezifisch gewünschte Einstellungen wie Preis, Länge aus
-
https://www.aboutyou.de/robots.txt: die Seite schließt gezielt Filterparameter aus
Was ist beim hreflang Einsatz bei Filter Seiten zu beachten?
Allgemein gilt auf Seiten:
hreflang-Tags sollten nur auf indexierbaren Seiten enthalten sein (HTTP-Statuscode 200, kanonisches Tag leer oder selbstreferenzierend, Meta-Robots leer oder Index eingeschlossen.)
Das heißt:
- Wenn der HTTP-Statuscode ≠ 200 ist, sollten keine hreflang-Tags genutzt werden! Beispielsweise sollten bei Weiterleitungen die hreflang Tags auf die endgültige Seite verweisen und diese verweist wieder zurück. Beim falschen Referrer kann Google das nicht richtig zurodnen.
- Wenn Meta Robots = noindex oder noindex, follow oder noindex, nofollow sollten Hreflang-Tags nicht berücksichtigt werden. Wenn die Seite schon nicht im Index ist, sollten auf weitere Optionen wie hreflang verzichtet werden, um u.a. Crawling Budget effizient zu steuern. Es gibt allerdings auch Einzelfälle, wo es anders gehandhabt wird.
- Wenn das kanonische Tag nicht auf sich selbst verweist – Hreflang-Tags nicht nutzen!
Vor allem die beiden letztgenannten Punkte entsprechen meisten den Eigenschaften von Filterparametern.
Bestehen noch Fragen? Hinterlasse mir doch einfach eine Nachricht oder nimm mit mir über das Kontaktformular Kontakt auf. Ich helfe dir mit meinem Expertenwissen.

Khoa Nguyen
Online Marketing Experte aus München
5,0 von 5
26 Bewertungen auf provenexpert.com

